alex-strae.github.io
Super Deliveries API
The goal of the program is to find the shortest possible delivery route for the highest valuable combination of orders. The program achieves this using the A* search algorithm, a dynamic knapsack solution and other logic. The user may: 1) Add, update or delete a custom order to the database and get all existing orders and 40 addresses from the database. 2) A unique, randomized delivery address is attached to each order. A graph is created from the addresses. 3) Optional: Choose a weight limit, as if you were delivering by bicycle for example, and get the most valuable combination of orders that meets the weight requirement. This is done through a dynamic implementation of the knapsack solution that allows you to get not only a total value, but the order(s) the value come from. POST orders to evaluate and receive the most valuable orders. 4) POST your orders and have the fastest route returned to you with its total distance, as well as the distance for other, simpler to calculate, delivery routes. Compare the distances; was the ‘Super Deliveries’ method the best?
Third-party libraries
Super Deliveries uses the flask framework and SQLAlchemy. The following third-party library imports are made:
from flask import Flask, requestfrom flask_restful import Api, Resourcefrom flask_jsonpify import jsonifyfrom sqlalchemy import create_engine, textfrom sorcery import dict_of
End points
Super Deliveries is a RESTful application, meaning any end point can be called at any time, as long as the appropriate data is fed. These end points are available:
/orders
All CRUD operations; Create, Read, Update and Delete any order in the database.
- Sending a GET will return a JSON of all rows with columns id, name, weight, value and address in table orders. IMPORTANT: Every time you send a GET to /orders, the orders will have new, randomized delivery addresses in respective ‘address’ field.
- POSTing requires a JSON with (unique) id, name, weight and value parameters. You can POST several orders in one go. Returns the same JSON.
- PUTting requires a JSON with already existing id, name, weight and value parameters. Returns the same JSON and status 200 if id existed. Returns same JSON and status 403 if not.
- Sending a DELETE requires no JSON - instead, send the request to /orders/{id} , {id} being the id of the order you’d have deleted. Returns null.
/addresses
Supports GET. Returns all rows with columns id, name, coordinate_x and coordinate_y from table ‘addresses’.
/limitingFactor/{factor}
Supports POST. Requires JSON of all orders to be considered and POST to /limitingFactor/{factor}, with {factor} being the weight limit. For example, ~/limitingFactor/22 to set a weight limit of 22 kilos. Returns a new JSON with a combination of orders that in total meets the weight requirement and with the highest total value.
/runTrip
Supports POST. Requires JSON of orders to calculate. Returns new JSON with:
- Calculated distances for all delivery methods. Compare them and see which one was best.
- Location of the logistics office
- The path the program traveled when delivering orders according to the Super Deliveries method
- Counters for total times Super Deliveries provided the best, shortest route and total calculation runs.
In practice:
1) Add, update or delete any orders as you please, then GET all orders 2) If you want, POST a JSON of the orders to the knapsack (limitingFactor endpoint) and have the most valuable combination returned that meets specified weight requirement. 3) GET all addresses. Using the provided coordinates in each address you can populate a table (a 2D-map) of 4 rows and 10 columns of addresses. You now have a table of all addresses, and all destinations since each order have a delivery address attached to it. 4) Get the final results by POSTING JSON of chosen orders to getResults. Update your table with the final path the program traveled.
Testing
The program have unit tests implemented on the dynamic knapsack solution, the database connection and the A* search algorithm.
How does the ‘Super Deliveries’ method work?
1) It sorts the deliveries, starting with the direction proceeding a direction void of deliveries (if any). If all directions have deliveries, it starts with the direction with fewest deliveries. Then it travels clockwise on the delivery map. 2) After each delivery, it chooses the next delivery address that is closest to current position, as long as that address is in the same direction. 3) After delivering the last order in the current direction, it chooses the closest delivery address in next clockwise direction, and then repeats the second stage. Unless there are no deliveries left.
- Since the starting direction was proceeding one (or more) directions without deliveries, if any such existed, the route will skip as many empty areas as possible. 4) The route finally returns to base.
This produces a nice, circle-shaped route with few, if any, zig-zag patterns, in about 90% of the cases. See below for ‘Can the SP method fail?’
How is the distance calculated using the other methods?
- The distance_by_foot is calculated by delivering the orders one by one, going back and forth from the logistics office.
- The distance_by_shortest is sorted in ascending order, starting with the delivery closest to the office, and ending with the one furthest away. Very effective if deliveries are all in the same direction. Very inefficient if not, as it produces a zig-zag delivery pattern.
- The distance_by_direction is sorted after direction. The program looks in the north direction first and then travels clockwise. Effective overall, but can unnecessarily move over empty areas in order to reach next delivery, and may have to go “back and forth” inside respective direction.
- All routes return to base in the end and have that distance in consideration.
Can the ‘Super Deliveries’ method fail to provide the fastest route?
Yes, it can. Sometimes, when the calculated orders are few, the ‘clockwise’ or the ‘shortest by direction’ method can get very favorable randomized addresses. If all addresses are in the same direction, the ‘shortest by direction’ method is tough to beat. Likewise, if the deliveries are in the North to South-East, the ‘Super Deliveries’ method gains no advantage over basic clockwise ‘sorted by direction’ since they both skip the void areas (‘sorted by direction’ always looks in the North first).
The finding of the closest target can actually result in a longer distance traveled:
Let’s say the ‘Super Deliveries’ method is in the middle of the East district and starts targeting the next delivery. One of them is closer to the office than the other, but they are equally far from the current location. The program then chooses the last address considered and moves further away from the office. It then has to travel back, closer to the office again to reach the last order in the direction area. Then, it turns out the next area of direction (South-East) have orders very far away. The program has to travel out from the center of the map yet again in order to go there.
Since the orders considered were equally far away, it would have been better targeting the innermost order closest to the office first, then the order in between, then the one further out, and lastly move to the next area of delivery orders, already being on the way there. ‘Super Deliveries’ do not account for this. On the other hand, if the next direction of orders would have been closer to the center of the map, the impact on the total distance would have been less, perhaps even favorable.
Super Deliveries yields the best result in >80% of the time for few orders and 95% of the time for many orders. When it misses, it only miss by a few kilometers compared to the winning method.
Other
-
Behind the scenes, the program creates a graph of addresses from addresses in the database. Based on the coordinates of the address, every address is awarded a direction from current logistics office. When using default addresses and without changing the logistics office variable, the logistics office address is in the center of the “map”.
-
The dynamic knapsack solution not only saves a total value inside a 2d-array but a list of the orders this value came from. This is what allows the program to return a JSON with not just a maximum total value number for given weight, but the orders this value is derived from.
-
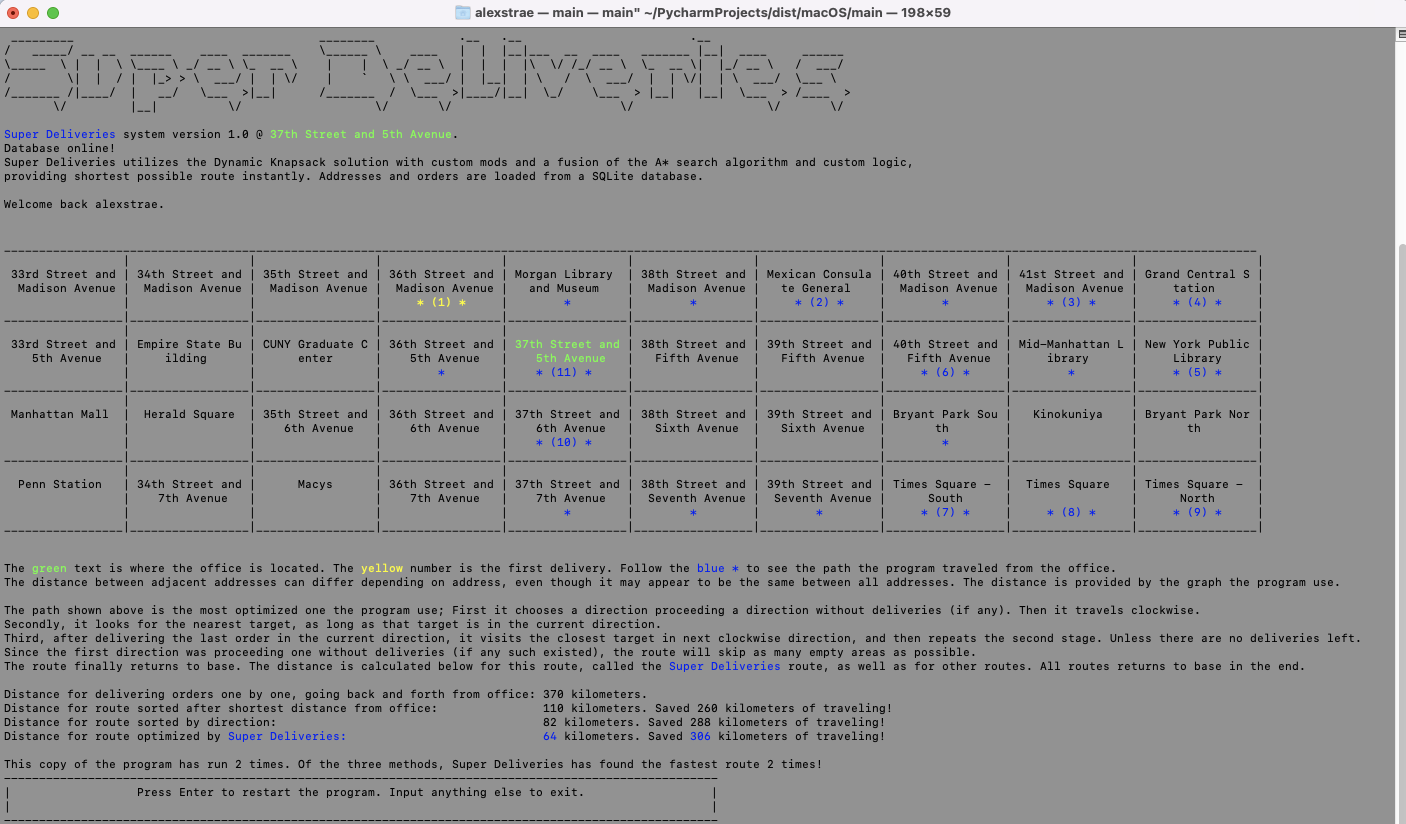
The orignal Super Deliveries with a GUI, shown below, was developed in 5 days. The API version is a rewrite and took a couple more days. Some additional hours have been spent finding and squashing bugs.
-
Future versions:
It would be awesome indeed to load a zone from the Google Maps API have the program use that as its graph for and source of delivery addresses.
More default orders in the db
A fancy, polished front-end
Adding the factor of storing orders while on the way to the logistics office, for a program more in accordance to JIT-delivery.
The ability to add more than one driver and optimizing deliveries based on delivery zones.
An example of how a frontend of this can look
The screenshot below is from the GUI version of Super Deliveries which is available in its own repository.
The code is more polished in the API version, however for purposes where you want to render a 2D-map in terminal, feel free to dive into the code in the GUI version.